publications
2024
 Li, Xiaolong, Mo, Jiawei, Wang, Ying, Parameshwara, Chethan, Fei, Xiaohan, Swaminathan, Ashwin, Taylor, CJ, Tu, Zhuowen, Favaro, Paolo, and Soatto, StefanoGrounded Compositional and Diverse Text-to-3D with Pretrained Multi-View Diffusion ModelarXiv preprint arXiv:2404.18065 2024
Li, Xiaolong, Mo, Jiawei, Wang, Ying, Parameshwara, Chethan, Fei, Xiaohan, Swaminathan, Ashwin, Taylor, CJ, Tu, Zhuowen, Favaro, Paolo, and Soatto, StefanoGrounded Compositional and Diverse Text-to-3D with Pretrained Multi-View Diffusion ModelarXiv preprint arXiv:2404.18065 2024We propose an effective two-stage approach named Grounded-Dreamer to generate 3D assets that can accurately follow complex, compositional text prompts while achieving high fidelity by using a pre-trained multi-view diffusion model..
2023
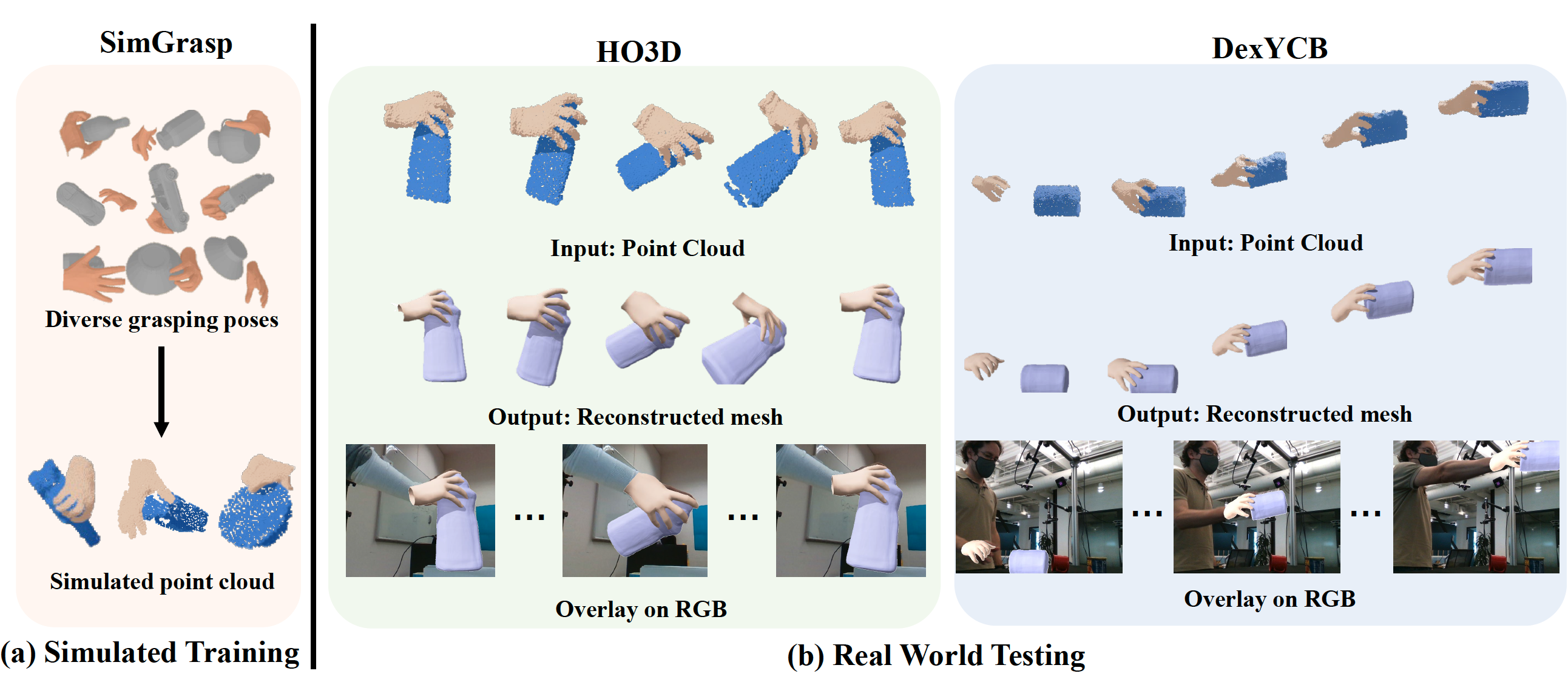 Chen, Jiayi, Yan, Mi, Zhang, Jiazhao, Xu, Yinzhen, Li, Xiaolong, Weng, Yijia, Yi, Li, Song, Shuran, and Wang, HeTracking and reconstructing hand object interactions from point cloud sequences in the wildIn Proceedings of the AAAI Conference on Artificial Intelligence 2023
Chen, Jiayi, Yan, Mi, Zhang, Jiazhao, Xu, Yinzhen, Li, Xiaolong, Weng, Yijia, Yi, Li, Song, Shuran, and Wang, HeTracking and reconstructing hand object interactions from point cloud sequences in the wildIn Proceedings of the AAAI Conference on Artificial Intelligence 2023We tackle the challenging task of jointly tracking hand object pose and reconstructing their shapes from depth point cloud sequences in the wild, given the initial poses at frame 0.
 Parameshwara, Chethan, Achille, Alessandro, Trager, Matthew, Li, Xiaolong, Mo, Jiawei, Swaminathan, Ashwin, Taylor, CJ, Venkatraman, Dheera, Fei, Xiaohan, and Soatto, StefanoTowards visual foundational models of physical scenesarXiv preprint arXiv:2306.03727 2023
Parameshwara, Chethan, Achille, Alessandro, Trager, Matthew, Li, Xiaolong, Mo, Jiawei, Swaminathan, Ashwin, Taylor, CJ, Venkatraman, Dheera, Fei, Xiaohan, and Soatto, StefanoTowards visual foundational models of physical scenesarXiv preprint arXiv:2306.03727 2023We describe a first step towards learning general-purpose visual representations of physical scenes.
2022
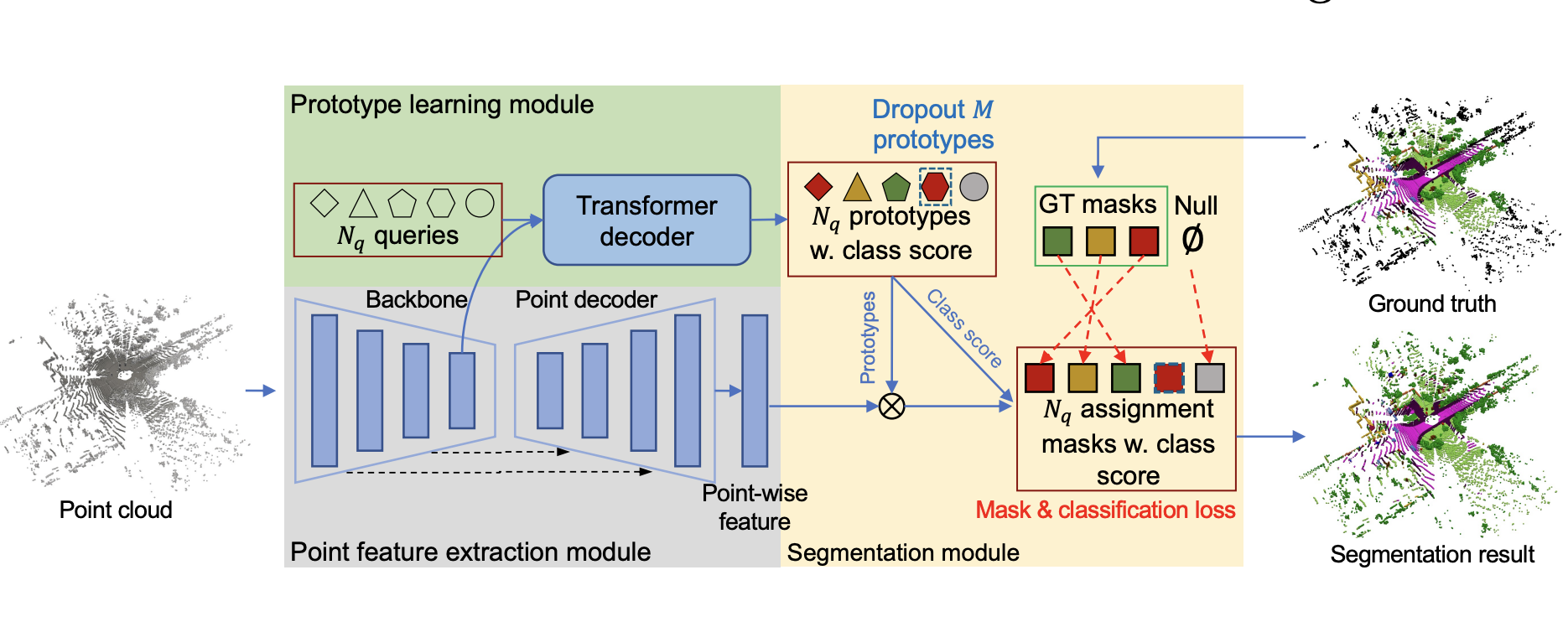 Zhao, Yangheng, Wang, Jun, Li, Xiaolong, Hu, Yue, Zhang, Ce, Wang, Yanfeng, and Chen, SihengNumber-adaptive prototype learning for 3d point cloud semantic segmentationIn European Conference on Computer Vision 2022
Zhao, Yangheng, Wang, Jun, Li, Xiaolong, Hu, Yue, Zhang, Ce, Wang, Yanfeng, and Chen, SihengNumber-adaptive prototype learning for 3d point cloud semantic segmentationIn European Conference on Computer Vision 2022Category-level object pose estimation aims to find 6D object.
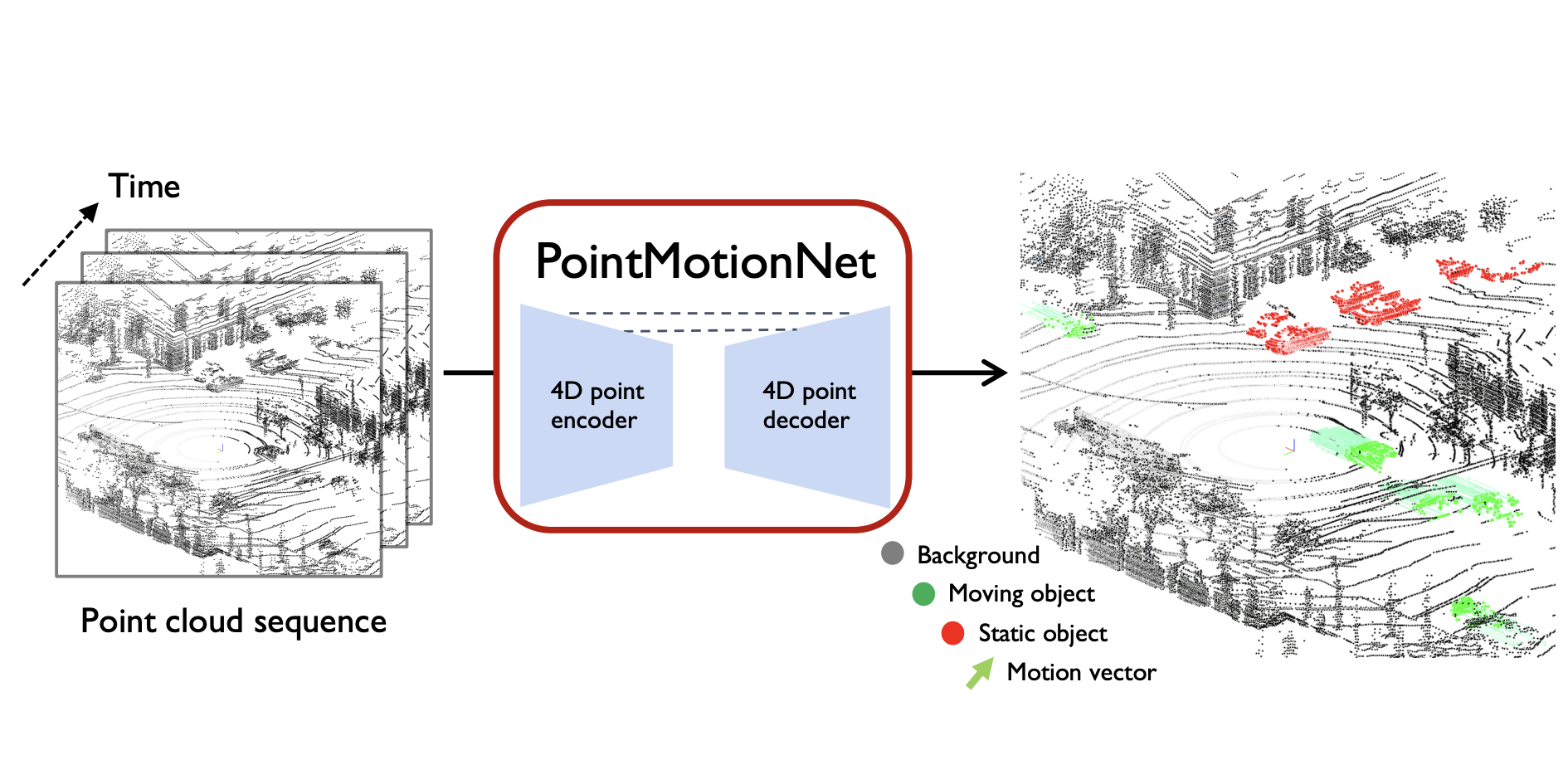 Wang, Jun, Li, Xiaolong, Sullivan, Alan, Abbott, Lynn, and Chen, SihengPointmotionnet: Point-wise motion learning for large-scale lidar point clouds sequencesIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022
Wang, Jun, Li, Xiaolong, Sullivan, Alan, Abbott, Lynn, and Chen, SihengPointmotionnet: Point-wise motion learning for large-scale lidar point clouds sequencesIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022Category-level object pose estimation aims to find 6D object poses of previously unseen object instances from known categories without access to object CAD models. To reduce the huge amount of pose annotations needed for category-level learning, we propose for the first time a self-supervised learning framework to estimate category-level 6D object pose from single 3D point clouds. During training, our method assumes no ground-truth pose annotations, no CAD models, and no multi-view supervision. The key to our method is to disentangle shape and pose through an invariant shape reconstruction module and an equivariant pose estimation module, empowered by SE(3) equivariant point cloud networks. The invariant shape reconstruction module learns to perform aligned reconstructions, yielding a category-level reference frame without using any annotations. In addition,the equivariant pose estimation module achieves category-level pose estimation accuracy that is comparable to some fully supervised methods. Extensive experiments demonstrate the effectiveness of our approach on both complete and partialdepth point clouds from the ModelNet40 benchmark, and on real depth point cloudsfrom the NOCS-REAL 275 dataset.
2021
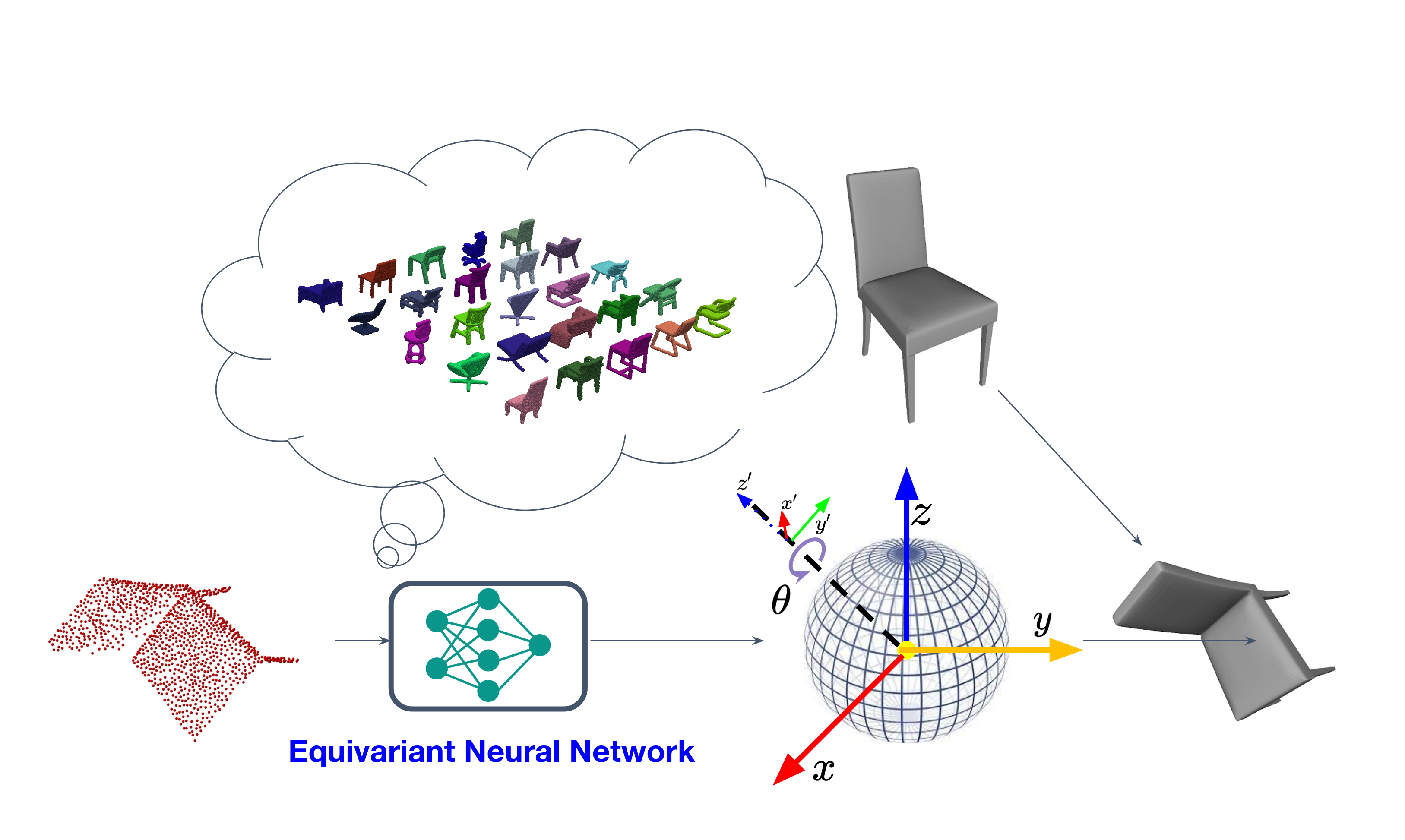 Li, Xiaolong, Weng, Yijia, Yi, Li, Guibas, Leonidas, Abbott, A Lynn, Song, Shuran, and Wang, HeLeveraging SE (3) Equivariance for Self-Supervised Category-Level Object Pose EstimationNeurIPS 2021
Li, Xiaolong, Weng, Yijia, Yi, Li, Guibas, Leonidas, Abbott, A Lynn, Song, Shuran, and Wang, HeLeveraging SE (3) Equivariance for Self-Supervised Category-Level Object Pose EstimationNeurIPS 2021Category-level object pose estimation aims to find 6D object poses of previously unseen object instances from known categories without access to object CAD models. To reduce the huge amount of pose annotations needed for category-level learning, we propose for the first time a self-supervised learning framework to estimate category-level 6D object pose from single 3D point clouds. During training, our method assumes no ground-truth pose annotations, no CAD models, and no multi-view supervision. The key to our method is to disentangle shape and pose through an invariant shape reconstruction module and an equivariant pose estimation module, empowered by SE(3) equivariant point cloud networks. The invariant shape reconstruction module learns to perform aligned reconstructions, yielding a category-level reference frame without using any annotations. In addition,the equivariant pose estimation module achieves category-level pose estimation accuracy that is comparable to some fully supervised methods. Extensive experiments demonstrate the effectiveness of our approach on both complete and partialdepth point clouds from the ModelNet40 benchmark, and on real depth point cloudsfrom the NOCS-REAL 275 dataset.
2020
 Li, Xiaolong, Wang, He, Yi, Li, Guibas, Leonidas J, Abbott, A Lynn, and Song, ShuranCategory-Level Articulated Object Pose EstimationCVPR 2020Oral Presentation(5.1%)
Li, Xiaolong, Wang, He, Yi, Li, Guibas, Leonidas J, Abbott, A Lynn, and Song, ShuranCategory-Level Articulated Object Pose EstimationCVPR 2020Oral Presentation(5.1%)This paper addresses the task of category-level pose estimation for articulated objects from a single depth image. We present a novel category-level approach that correctly accommodates object instances previously unseen during training. We introduce Articulation-aware Normalized Coordinate Space Hierarchy (ANCSH) – a canonical representation for different articulated objects in a given category. As the key to achieve intra-category general- ization, the representation constructs a canonical object space as well as a set of canonical part spaces. The canonical object space normalizes the object orientation, scales and articulations (e.g. joint parameters and states) while each canonical part space further normalizes its part pose and scale. We develop a deep network based on PointNet++ that predicts ANCSH from a single depth point cloud, including part segmentation, normalized coordi- nates, and joint parameters in the canonical object space. By leveraging the canonicalized joints, we demonstrate: 1) improved performance in part pose and scale estimations using the induced kinematic constraints from joints; 2) high accuracy for joint parameter estimation in camera space
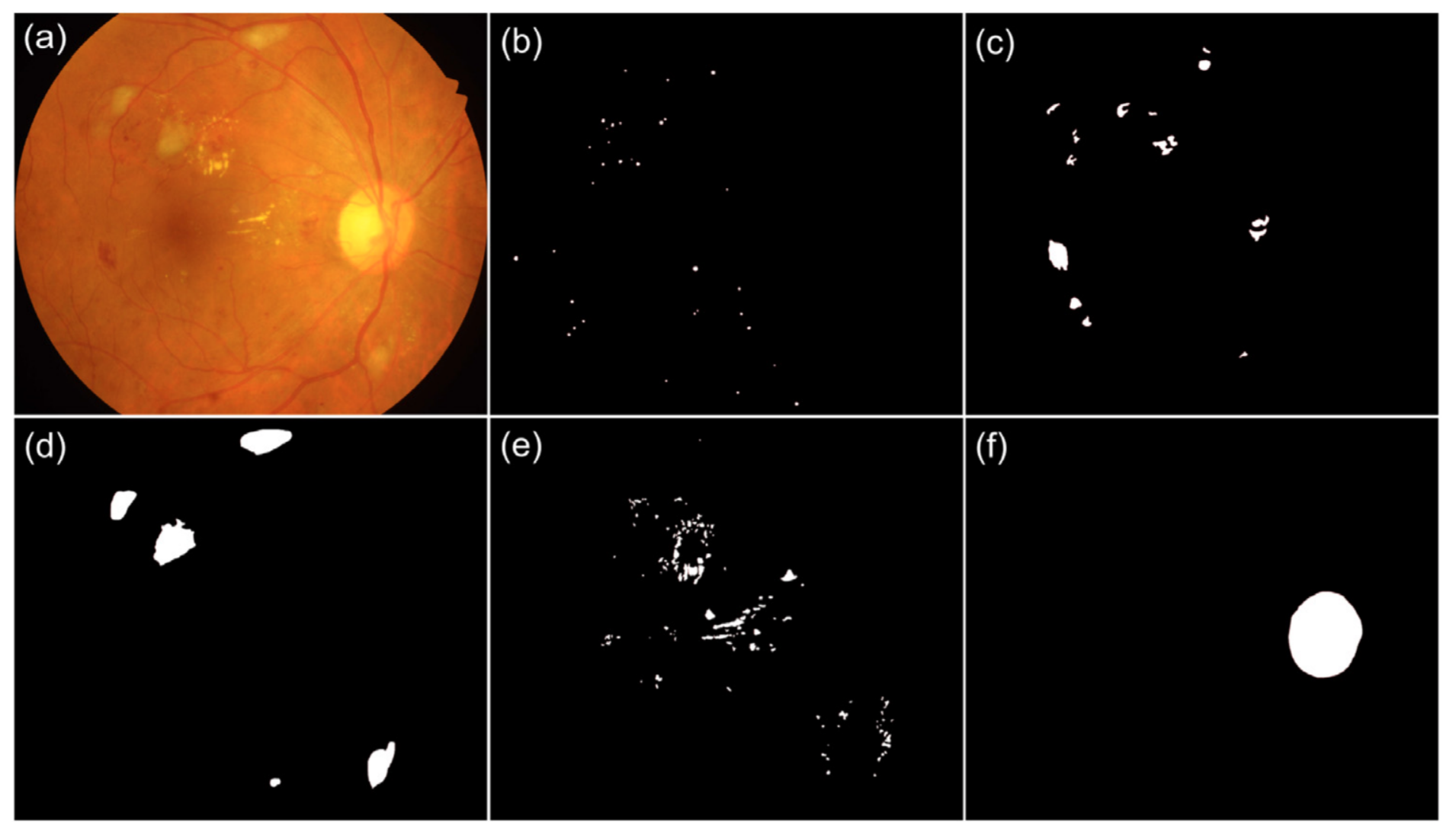 Porwal, Prasanna, Pachade, Samiksha, Kokare, Manesh, Deshmukh, Girish .., Li, Xiaolong, and others,Idrid: Diabetic retinopathy–segmentation and grading challengeMedical image analysis 2020
Porwal, Prasanna, Pachade, Samiksha, Kokare, Manesh, Deshmukh, Girish .., Li, Xiaolong, and others,Idrid: Diabetic retinopathy–segmentation and grading challengeMedical image analysis 2020Diabetic Retinopathy (DR) is the most common cause of avoidable vision loss, predominantly affecting the working-age population across the globe. Screening for DR, coupled with timely consultation and treatment, is a globally trusted policy to avoid vision loss. However, implementation of DR screening programs is challenging due to the scarcity of medical professionals able to screen a growing global diabetic population at risk for DR. Computer-aided disease diagnosis in retinal image analysis could provide a sustainable approach for such large-scale screening effort. The recent scientific advances in computing capacity and machine learning approaches provide an avenue for biomedical scientists to reach this goal. Aiming to advance the state-of-the-art in automatic DR diagnosis, a grand challenge on “Diabetic Retinopathy – Segmentation and Grading” was organized in conjunction with the IEEE International Symposium on Biomedical Imaging (ISBI - 2018). In this paper, we report the set-up and results of this challenge that is primarily based on Indian Diabetic Retinopathy Image Dataset (IDRiD). There were three principal sub-challenges: lesion segmentation, disease severity grading, and localization of retinal landmarks and segmentation. These multiple tasks in this challenge allow to test the generalizability of algorithms, and this is what makes it different from existing ones. It received a positive response from the scientific community with 148 submissions from 495 registrations effectively entered in this challenge. This paper outlines the challenge, its organization, the dataset used, evaluation methods and results of top-performing participating solutions. The top-performing approaches utilized a blend of clinical information, data augmentation, and an ensemble of models. These findings have the potential to enable new developments in retinal image analysis and image-based DR screening in particular.
2017
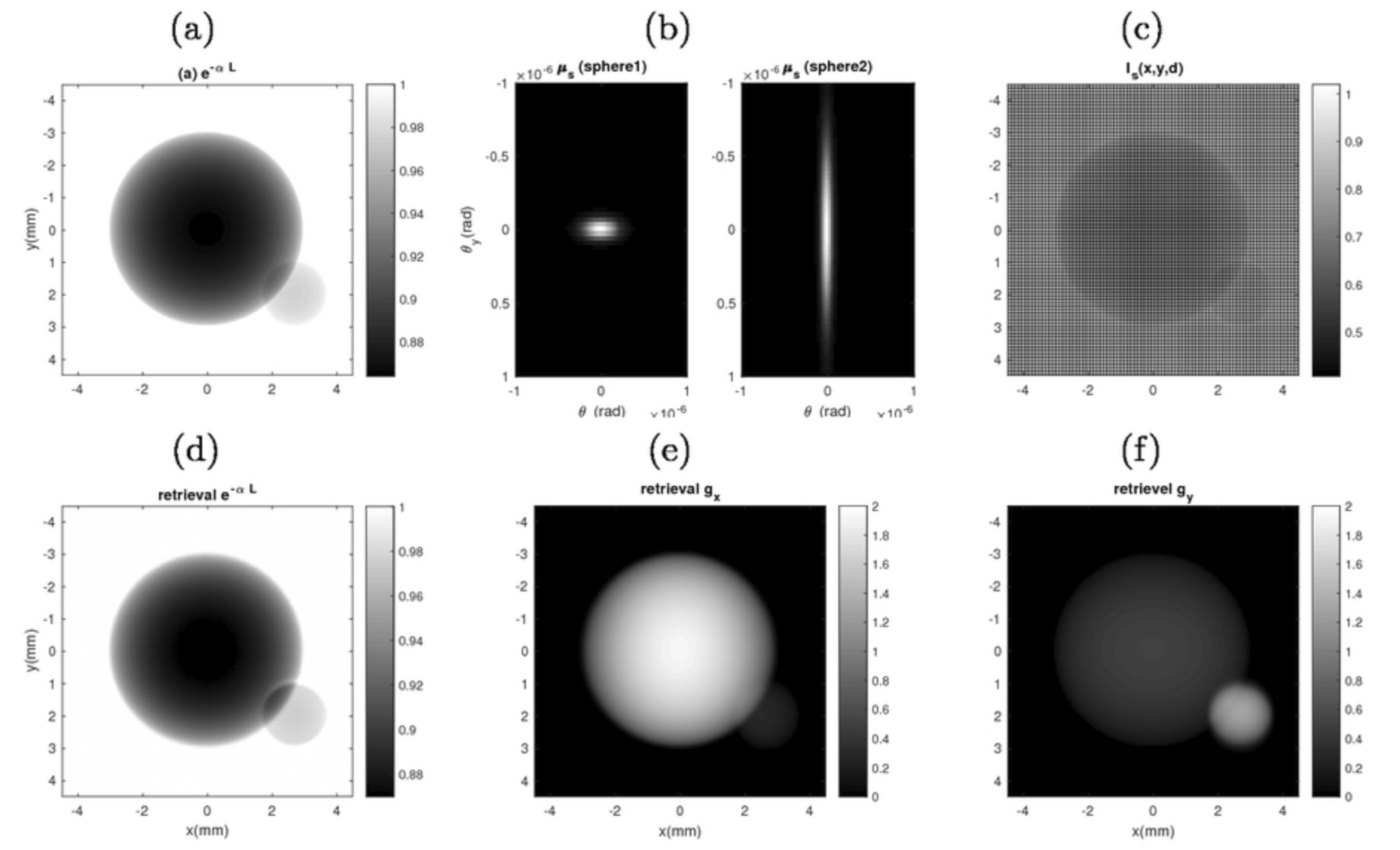 Wu, Ziling, Li, Xiaolong, and Zhu, YunhuiTexture orientation-resolving imaging with structure illuminationIn Computational Imaging II 2017
Wu, Ziling, Li, Xiaolong, and Zhu, YunhuiTexture orientation-resolving imaging with structure illuminationIn Computational Imaging II 2017
2015
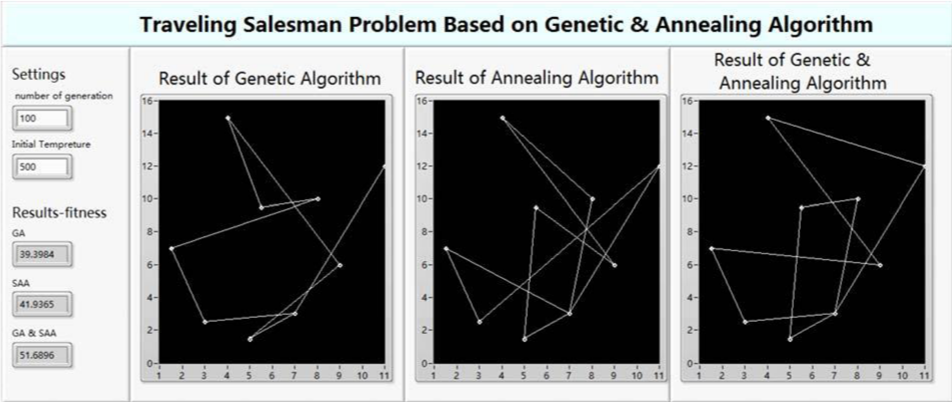 Chen, Muhao, Gong, Chen, Li, Xiaolong, and Yu, ZongxinResearch on solving Traveling Salesman Problem based on virtual instrument technology and genetic-annealing algorithmsIn 2015 Chinese Automation Congress (CAC) 2015
Chen, Muhao, Gong, Chen, Li, Xiaolong, and Yu, ZongxinResearch on solving Traveling Salesman Problem based on virtual instrument technology and genetic-annealing algorithmsIn 2015 Chinese Automation Congress (CAC) 2015